
OpenResearch · Community
Public Projects
Auto-research projects shared by the community, many reproducing recent arXiv papers end to end. Open one to explore its experiment graph, runs, and results.
 2606.25996
2606.25996Autodata: An agentic data scientist to create high quality synthetic data
Autodata: An agentic data scientist to create high quality synthetic data
EB-Dissei/autodata-an-agentic-data-scientist-to-create-high-quality-sy-6d79ff62HBS Cases
Agentic Self-Instruct for hard finance reasoning. Generates hindsight-free, certified-hard finance-reasoning items (tier-weighted rubrics) grounded in the neutral pre-anchor materials of real HBS-style case studies (NTS/Oaktree mezzanine + 8 others, 42 case-anchor units). Compares CoT vs Agentic generation on the strong-weak solver gap. CPU-only, pure-stdlib LLM-API pipeline.
EB-Dissei/test-96d82f4a 2510.25107
2510.25107Learning Hamiltonian flows from numerical integrators and examples
Learning Hamiltonian flows from numerical integrators and examples
putintostyle/learning-hamiltonian-flows-from-numerical-integrators-and-ex-214c5287video-search-and-summarization
NVIDIA-AI-Blueprints/video-search-and-summarization
johnmarkwendler/video-search-and-summarization-efc4a39a 2606.14150
2606.14150llm-pruning-collection
Small LLMs: Pruning vs. Training from Scratch
69mannying/llm-pruning-collection-5ca63e4b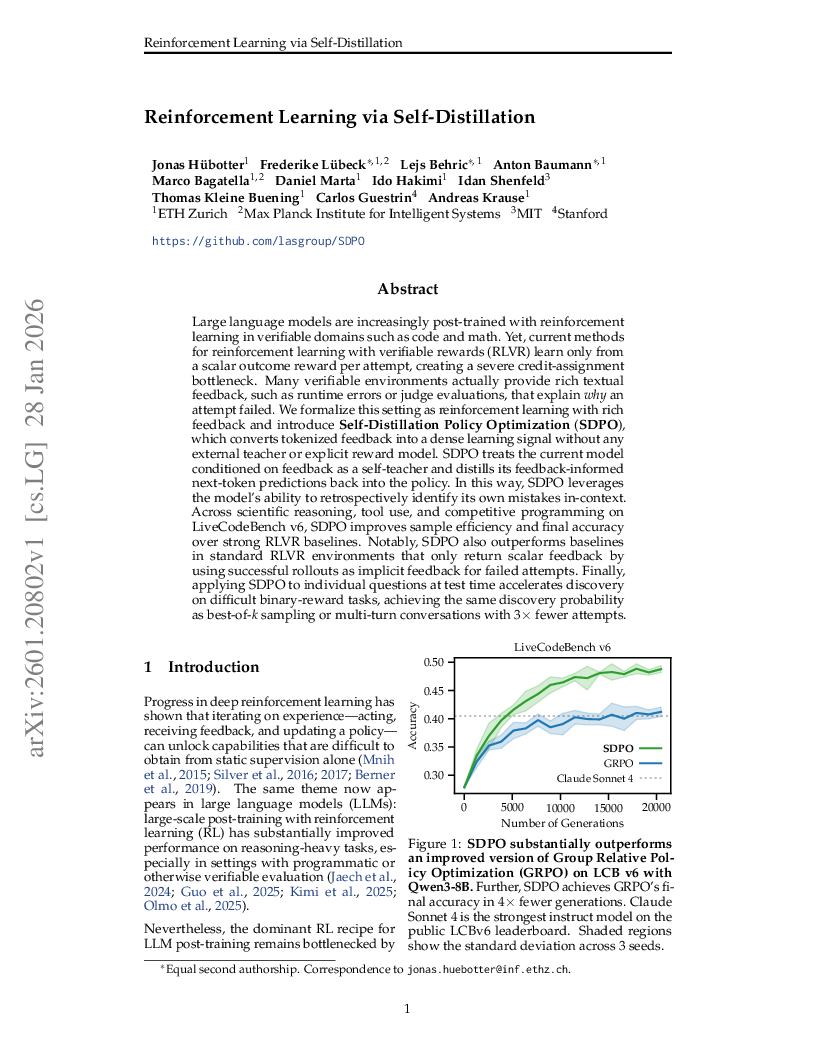 2601.20802
2601.20802GLM SDPO
Reinforcement Learning via Self-Distillation
alphaXiv/sdpo-72dc8b282601.20802Opus SDPO
Reinforcement Learning via Self-Distillation
alphaXiv/sdpo-523abdd1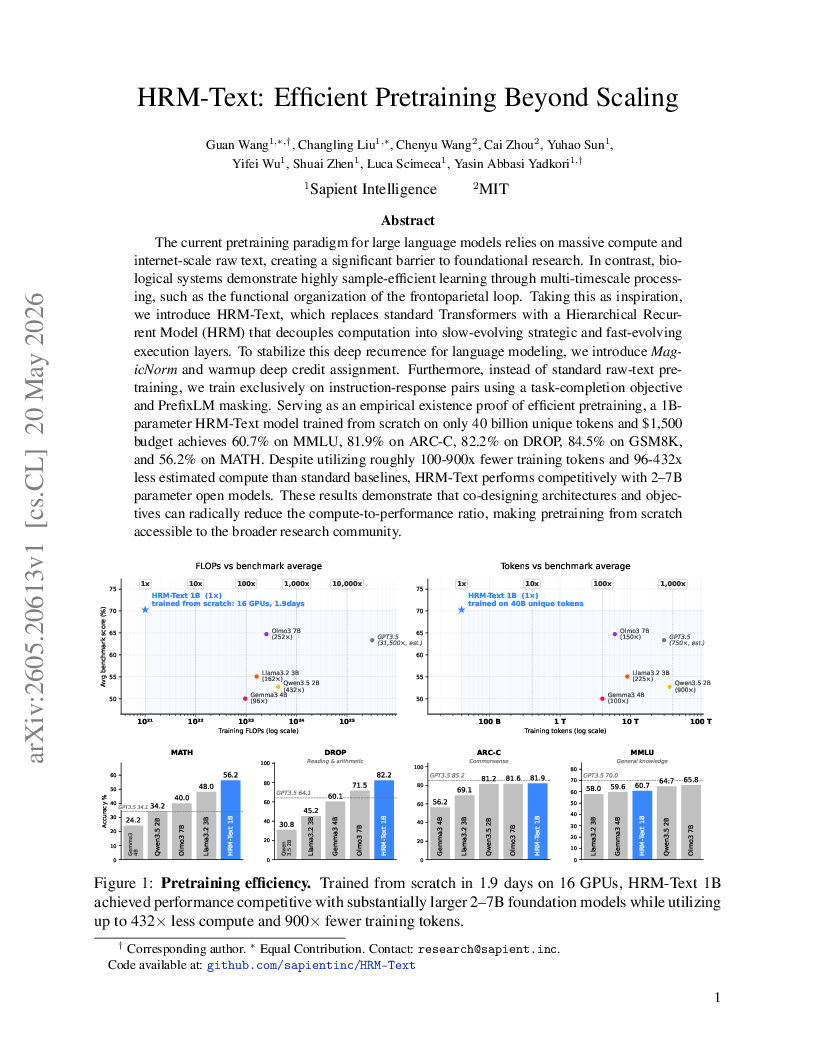 2605.20613
2605.20613HRM-Text
HRM-Text: Efficient Pretraining Beyond Scaling
surfiend/hrm-text-57368411nanochat
基线已从 alphaXiv/nanochat 导入
ryzonic/nanochat-49a21351 2602.14486
2602.14486Aristotelian
Revisiting the Platonic Representation Hypothesis: An Aristotelian View
69mannying/aristotelian-19860a06 2510.03154
2510.03154EditLens
EditLens: Quantifying the Extent of AI Editing in Text
69mannying/editlens-393024d5 2604.08423
2604.08423dataset-policy-gradients
Synthetic Data for any Differentiable Target
69mannying/dataset-policy-gradients-56b37a2b 2606.23565
2606.23565HoloAgent
HoloAgent-0: A Unified Embodied Agent Framework with 3D Spatial Memory
alphaXiv/holoagent 2606.23050
2606.23050Unlimited-OCR
Unlimited OCR Works
alphaXiv/unlimited-ocr 2606.20008
2606.20008VIMPO
VIMPO: Value-Implicit Policy Optimization for LLMs
alphaXiv/vimpo 2504.16084
2504.16084ttrl-2139857f-505bba71
TTRL: Test-Time Reinforcement Learning
bmjb169-bit/ttrl-2139857f-505bba71-29474ca3 2403.15734
2403.15734CrystalFormer
Space Group Informed Transformer for Crystalline Materials Generation
Osgood001/crystalformer-a9eb300e2504.16084TTRL
TTRL: Test-Time Reinforcement Learning
yihanzipu-sys/ttrl-2139857f 2606.13795
2606.13795DiPOD-release
DiPOD: Diffusion Policy Optimization without Drifting Apart
manbeastfurryfreedom-ctrl/dipod-release-e361cc37 2307.11628
2307.11628Rethinking Mesh Watermark: Towards Highly Robust and Adaptable Deep 3D Mesh Wate
Rethinking Mesh Watermark: Towards Highly Robust and Adaptable Deep 3D Mesh Watermarking
feelthevenom/rethinking-mesh-watermark-towards-highly-robust-and-adaptabl-87a39587 2605.13959
2605.13959WarmPrior: Straightening Flow-Matching Policies with Temporal Priors
WarmPrior: Straightening Flow-Matching Policies with Temporal Priors
axiat/warmprior-straightening-flow-matching-policies-with-temporal-d3d08ed6SkyRL
Getting SkyRL's fully-async GSM8K RL training running end-to-end on multi-GPU.
rehaanahmad2013/skyrl-91b191e9 2606.16140
2606.16140VibeThinker
VibeThinker-3B: Exploring the Frontier of Verifiable Reasoning in Small Language Models
jyotinayarman/vibethinker-dfc26b68 2606.17551
2606.17551rql
Reversal Q-Learning
rehaanahmad2013/rql-08edae95 2512.13874
2512.13874SAGE
SAGE: Training Smart Any-Horizon Agents for Long Video Reasoning with Reinforcement Learning
johnmarkwendler/sage-9566147f 2606.19531
2606.19531ImageWAM
ImageWAM: Do World Action Models Really Need Video Generation, or Just Image Editing?
rehaanahmad2013/imagewam-734ca7542601.20802SDPO
Reinforcement Learning via Self-Distillation
AndyML-stuff/sdpo-fede389f 2601.18734
2601.18734OPSD
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
69mannying/opsd-d03af96d2606.16140VibeThinker-3B
Reproduce VibeThinker-3B frontier reasoning claim (arXiv 2606.16140): minimal vLLM eval of the released 3B model on AIME25.
alphaXiv/vibethinker-eb715d63 2606.15956
2606.15956TDV
Reproduction of TDV (arXiv 2606.15956): temporal-difference video self-supervised learning.
alphaXiv/tdv-078f9e7d 2606.14702
2606.14702OmniVideo-100K
Reproduction of the OmniVideo-100K audio-visual data engine (arXiv 2606.14702)
alphaXiv/omnivideo-100k-bc18a0b4 2606.16993
2606.16993DreamX-World
Reproduction of DreamX-World (arXiv 2606.16993): autoregressive 5B camera-controlled image-to-video generation, 4-step distilled.
alphaXiv/dreamx-world-3ea33dafEvoArena
Reproduction of EvoArena (arXiv 2606.13681): EvoMem patch-memory vs robust baseline on PersonaMem-Evo.
alphaXiv/evoarena-42c71d1eOPD Param Analysis
Reproduction of OPD parameter analysis (arXiv 2606.13657): on-policy vs offline weight-delta (ΔW) structure on released model pairs.
alphaXiv/opd-param-analysis-2462f2c3 2606.14409
2606.14409Hy-Embodied-0.5-VLA
Reproduction of Hy-Embodied-0.5-VLA (arXiv 2606.14409): flow-matching vision-language-action model; action-chunk reconstruction PoC.
alphaXiv/hy-embodied-0-5-vla-14acd04b 2606.12370
2606.12370Bebop MTP TV-Loss
Reproduce the core claim of 2606.12370 (Bebop): training an EAGLE3/MTP draft head with the paper's TV / e2e-TV loss yields higher rejection-sampling acceptance and a flatter entropy-acceptance slope than the CE baseline. Minimal single-GPU PoC on open Qwen3.
alphaXiv/specforge-e6f78362 2606.10650
2606.10650Dynamic Linear Attention
Reproduction of DLA (arXiv 2606.10650) on top of the Log-Linear Attention codebase it builds on.
alphaXiv/log-linear-attention-8a7ec22c 2606.12507
2606.12507RGSD
Reproduce Rubric-Guided Self-Distillation (2606.12507): RGSD vs judge-based GRPO on RubricHub-medical, Qwen-2.5-3B-Instruct, on SkyRL. Judge=gpt-4o-mini via OpenRouter. Baseline=base+conditioning-lift; children=GRPO arm, RGSD arm.
alphaXiv/skyrl-ca3ca5cf-4208b8beChroma
Implementation of Chroma Context-1
alphaXiv/skyrl-ca3ca5cf 2603.28052
2603.28052Meta-Harness S2D
Reproduction of Meta-Harness (2603.28052): automated harness search for online text classification on Symptom2Disease. opencode proposer over OpenRouter; gpt-oss-20b base model.
alphaXiv/meta-harness-s2d-af14e8ec 2606.13652
2606.13652World Tracing
Reproduction of World Tracing (arXiv 2606.13652): object model predicting layered XYZ geometry, including occluded surfaces.
alphaXiv/world-tracing-e62e38ac 2606.11709
2606.11709RLCSD
Reproduction of RLCSD (arXiv 2606.11709): RL contrastive self-distillation with verl/vLLM on Qwen3-1.7B / DeepMath.
alphaXiv/rlcsd-9acf8246 2606.13392
2606.13392MiniMax Sparse Attention
Reproduction of MiniMax Sparse Attention (arXiv 2606.13392): CuTe-DSL sparse-attention kernel, sparse-vs-dense speedup PoC.
alphaXiv/msa-3f4986b6 2602.06036
2602.06036DFlash
Reproduction of DFlash (arXiv 2602.06036): block-diffusion draft model for speculative decoding on Qwen3-4B.
alphaXiv/dflash-b4d1109c 2603.19312
2603.19312LeWorldModel
Reproduction of LeWorldModel (arXiv 2603.19312): two-term JEPA world model on PushT.
alphaXiv/le-wm-66ffbe61 2606.03264
2606.03264PaddleOCR-VL-1.6
Reproduction of PaddleOCR-VL-1.6 (arXiv 2606.03264): compact 0.9B document-parsing VLM, SOTA on OmniDocBench v1.6.
alphaXiv/paddleocr-50e3c8c8 2606.11087
2606.11087Q-Guided Flow
Reproduction of Q-Guided Flow (arXiv 2606.11087): test-time critic-gradient guidance of a frozen BC flow policy in RL.
alphaXiv/qgf-12b912fc 2606.12195
2606.12195InternVideo3
Reproduction of InternVideo3 (arXiv 2606.12195): transformers-native text+image+video inference PoC for the 8B model.
alphaXiv/internvideo-d2a11ea9 2606.10651
2606.10651Keye-VL-2.0
Reproduction of Kwai Keye-VL-2.0 (arxiv 2606.10651): transformers-native multimodal inference PoC for the 30B-A3B MoE model.
alphaXiv/keye-39e1f0b5 2606.11722
2606.11722ICALens
Reproduction of arXiv 2606.11722: ICA Lens — interpreting LMs without training another dictionary
alphaXiv/ica-lens-paper-e1fdec2fSelf-Distilled Reasoner
Reproduction of On-Policy Self-Distillation (arXiv 2601.18734): self-distilled reasoner on Qwen3-1.7B.
rehaanahmad2013/opsd-96e22c23 2606.08432
2606.08432Trajectory-Refined Distillation
Reproduction of Trajectory-Refined Distillation (arXiv 2606.08432): forward-KL distillation on refined trajectories, Qwen3-1.7B.
alphaXiv/trd 2606.06021
2606.06021On-Policy Representation Distillation
Reproduction of On-Policy Representation Distillation (arXiv 2606.06021): representation-distillation PoC on a single GPU.
alphaXiv/on-policy-representation-distillation 2606.09079
2606.09079FlashMemory-DeepSeek-V4
Reproduction of FlashMemory-DeepSeek-V4 (arXiv 2606.09079): sparse-KV retriever + sparse-decode PoC.
alphaXiv/flashmemory-deepseek-v4 2606.02800
2606.02800Cosmos
Reproduction of Cosmos 3 (arXiv 2606.02800): Cosmos3-Nano text-to-image and text-to-video inference PoC.
alphaxiv/cosmosMaxRL Opus
GRPO vs MaxRL on GSM8K (Qwen3-1.7B + LoRA): comparing advantage normalization by group mean vs std.
rehaanahmad2013/qwen-maxrl-b7d23c6bMaxRL Fable
GRPO vs MaxRL on GSM8K (Qwen3-1.7B + LoRA): does normalizing the advantage by group mean instead of std help?
rehaanahmad2013/qwen-maxrl-b724706e